
DNS UDP Limitation
2023-05-07
⚠️ DNS over UDP: The Silent Limitation Wasting Your Resources
When you scale horizontally, whether it’s pods behind a headless service in Kubernetes or VMs behind a DNS-based load balancer, you probably assume all your instances are equally reachable. But there's a catch most miss until they start debugging strange connection drops…
DNS over UDP silently drops anything after ~8 A records.
Let’s break this down.
Quick Background: DNS & UDP
By default, DNS uses UDP, not TCP. That’s because it’s faster and usually sufficient for small requests/responses. But:
- UDP has a 512-byte payload size limit (RFC 1035).
- That means for a DNS A-record response, you’ll only get ~8 IPs max (depending on domain length and other metadata).
- If the record size exceeds that, the server sets a flag: "truncated", hinting that the full answer is available—but only over TCP.
Now here’s the kicker: most clients (e.g. dig, Kubernetes DNS, Go resolver, Python resolver, even libc-based resolvers) do not retry over TCP unless explicitly told to.
Problem In Action: Real Example
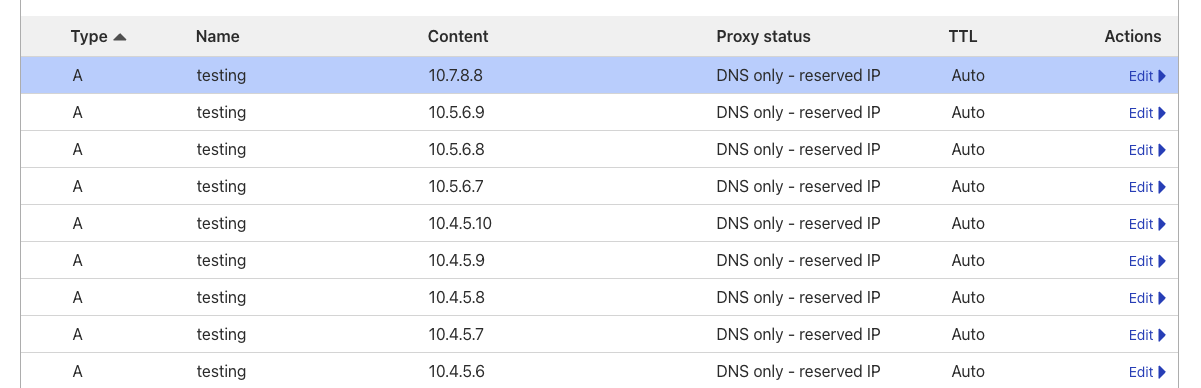
Take a look at this domain: testing.moabukar.co.uk
I’ve created 10 A records behind that domain, pointing to various internal IPs:
But when we run a dig:
dig testing.moabukar.co.uk
We only get 8 IPs back:
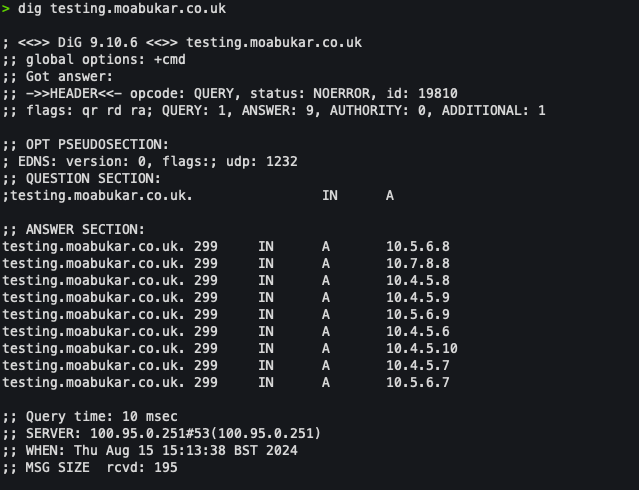
Despite the DNS backend (Cloudflare) holding all 10 entries, we never see more than 8.
This means 2 instances are completely unreachable from any client doing a standard UDP DNS query.
🛑 Why This Is Bad
- Wasted compute – The missing IPs are still running services and consuming resources.
- Reduced reliability – Your load balancer isn’t as balanced as you thought.
- Hidden bugs – Sporadic connectivity issues are hard to trace, especially when the resolution behavior is inconsistent across environments.
🔥 How to Reproduce
- Register a domain and use Cloudflare or Route53.
- Add 9+ A records with the same name (e.g. testing.example.com).
- Run
dig testing.example.com +short - Count the records returned when you run dig. You’ll likely see only 8.
💡 Solutions & Workarounds
✅ 1. Use TCP explicitly (when possible)
dig +tcp testing.example.com
But this isn’t viable for most client applications.
✅ 2. Use multiple DNS records (e.g. testing1, testing2) Shard your A records logically.
✅ 3. Use a Load Balancer or Ingress controller Let it manage the IP-to-service mapping, rather than relying on DNS for client-side load balancing.
✅ 4. Use SRV or CNAME (if app supports it) SRV records often use less space and allow port/service separation too.
✅ 5. Reduce number of targets behind a single DNS name For critical paths, consider spreading across multiple records.
How Kubernetes Handles This
Kubernetes headless services (ClusterIP: None) are backed by multiple A records pointing to pod IPs. This exact issue applies!
- If your headless service has >8 pods, some will be unreachable via DNS if your app relies on client-side balancing.
- Kube-proxy and service IP-based routing avoids this, but not all clients use it (e.g. StatefulSets that do direct DNS resolution).
Summary
UDP DNS resolution has a fundamental limitation:
- You only get as many A records as fit in 512 bytes—usually around 8 entries max.
- This can silently kill your scaling, break client-side discovery, and waste infrastructure.
Always audit your DNS queries when scaling out.